Surrogate model¶
Generalities¶
A common class is used to manage surrogate models. Hence, several kind of surrogate model strategies can be used:
predictor = batman.surrogate.SurrogateModel('kriging', corners)
predictor.fit(space, target_space)
predictor.save('.')
points = [(12.5, 56.8), (2.2, 5.3)]
predictions = predictor(points)
From Kriging to Gaussian Process¶
Kriging, a geostatistical method¶
Kriging is a geostatistical interpolation method that use not only the distance between the neighbouring points but also the relationships among these points, the autocorrelation. The method has been created by D.G. Krige [Krige1989] and has been formalized by G. Matheron [Matheron1963].
In order to predict an unmeasured location \(\hat{Y}\), interpolation methods use the surrounding measured values \(Y_i\) and weight them:
The advantage of this method is that the interpolation is exact at the sampled points and that it gives an estimation of the prediction error. Ordinary Kriging consists in the Best Linear Unbiased Predictor (BLUP) [Robinson1991]:
- Best
It minimizes the variance of the predicted error \(Var(\hat{Y} - Y)\),
- Linear
A linear combination of the data,
- Unbiased
It minimizes the mean square error \(E[\hat{Y} - Y]^2\) thus \(\sum_{i=1}^{N} \lambda_i(x)=1\),
- Predictor
It is an estimator of random effects.
\(\lambda_i\) are calculated using the spatial autocorrelation of the data, it is a variography analysis. Plots can be constructed using semivariance, covariance or correlation. An empirical variogram plot allows to see the values that should be alike because they are close to each other cite{Bohling2005}. The empirical semivariogram is given by:
A fitting model is then applied to this semivariogram. Hence, the variability of the model is inferior to data’s. Kriging smooths the gradients. The exponential model is written as:
with \(C\) the correlation matrice and the parameter \(r\) is optimized using the sample points.
A model is described using:
- Sill
It corresponds to the maximum of \(\gamma\). It defines the end of the range.
- Range
It is the zone of correlation. If the distance is superior to the range, there is no correlation, whereas if the distance is inferior to it, the sample locations are autocorrelated.
- Nugget
If the distance between the points is null, \(\gamma\) should be null. However, measurement errors are inherent and cause a nugget effect. It is the y-intercept of the model.
Once the model is computed, the weights are determined to use the MSE condition and gives:
\(K\) being the covariance matrix \(K_{i,j} = C(Y_i-Y_j)\) and \(k\) being the covariance vector \(k_i = C(Y_i-Y)\) with the covariance \(C(h) = C(0) - \gamma(h) = Sill-\gamma(h)\).
Furthermore we can express the field \(Y\) as \(\hat{Y} = R(S) + m(S)\) which is the residual and the trend components [Bohling2005]. Depending on the treatment of the trend, there are several Kriging techniques (ordinary Kriging being the most used):
- Simple
The variable is stationary, the mean is known,
- Ordinary
The variable is stationary, the mean is unknown,
- Universal
The variable is non-stationary, there is a tendency.
Ordinary Kriging is the most used method. In this case, the covariance matrix is augmented:
Once the weights are computed, its dot product with the residual \(R_i=Y_i-m\) at the known points gives the residual \(R(S)\). Thus we have an estimation of \(\hat{Y}\). Finally, the error is estimated by the second order moment:
Some care has to be taken with this estimation of the variance. Being a good indicator of the correctness of the estimation, this is only an estimation of the error based upon all surrounding points.
Gaussian Process¶
There are two approaches when dealing with regression problems. In simple cases, we can use simple functions in order to approximate the output set of data. On the other hand, when dealing with complex multidimensional problems with strong non-linearity, there are infinite possibilities of functions to consider. This is where the Gaussian process comes in.
As stated by Rasmussen et al. in [Rasmussen2006], a process is a generalization of a probability distribution of functions. When dealing with Gaussian processes, they can simply be fully defined using the mean and covariance of the functions:
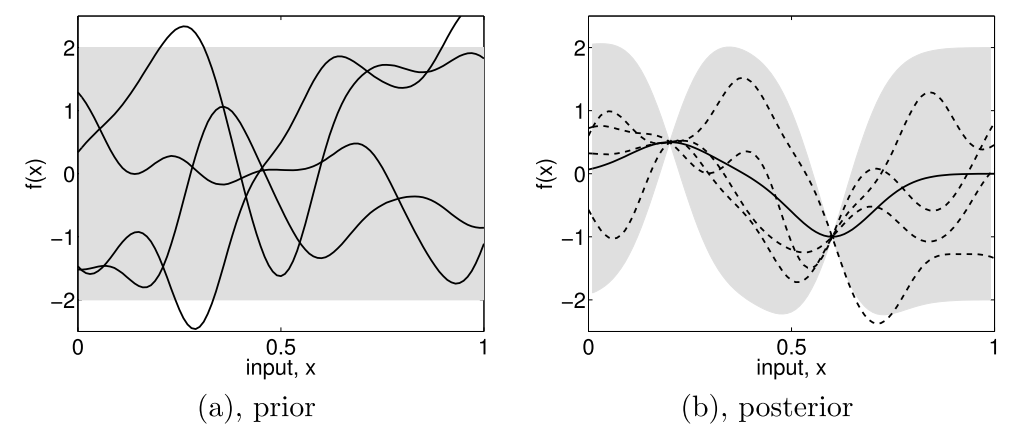
Subfigure (a) shows four samples from a prior distribution. (b) shows the situation after two observations have been made. [Rasmussen2006].¶
Starting from a prior distribution of functions, it represents the belief we have on the problem. Without any assumption, the mean would be null. If we are now given a dataset \(D = \{(x_1, y_1), (x_2, y_2)\}\), we only consider the function that actually pass through or close to these points, as in the previous figure. This is the learning phase. The more points are added, the more the model will fit the function. Indeed, as we add observations, the error is reduced at these points.
The nature of the covariance matrix is of great importance as it fixes the properties of the functions to consider for inference. This matrix is also called kernel. Many covariance functions exist and they can be combined to fit specific needs. A common choice is the squared exponential covariance kernel:
with \(l\) the length scale, an hyperparameter, which depends on the magnitudes of the parameters. When dealing with a multidimensional case and non-homogeneous parameters, it is of prime importance to adimentionize everything as one input could bias the optimization of the hyperparameters.
Then the Gaussian process regression is written as a linear regression
One of the main benefit of this method, is that it provides an information about the variance
The Kriging method is one of the most employed as of today. We can even enhance the result of the regression if we have access to the derivative (or even the hessian) of the function [Forrester2009]. This could be even more challenging if we don’t have an adjoint solver to compute it. Another method is to use a multi-fidelity metamodel in order to obtain an even better solution. This can be performed if we have two codes that compute the same thing or if we have two grids to run from.
Multifidelity¶
It is possible to combine several level of fidelity in order to lower the computational cost of the surrogate building process. The fidelity can be either expressed as a mesh difference, a convergence difference, or even a different set of solvers. [Forrester2006] proposed a way of combining these fidelities by building a low fidelity model and correct it using a model of the error:
with \(\hat{f}_{\epsilon}\) the surrogate model representing the error between the two fidelity levels. This method needs nested design of experiments for the error model to be computed.
Considering two levels of fidelity \(f_e\) and \(f_c\), respectively an expensive and a cheap function expressed as a computational cost. A cost ratio \(\alpha\) between the two can be defined as:
Using this cost relationship an setting a computational budget \(C\), it is possible to get a relation between the number of cheap and expensive realizations:
As the design being nested, the number of cheap experiments must be strictly superior to the number or expensive ones. Indeed, the opposite would result in no additional information to the system.
References¶
- Krige1989
D.G. Krige, et al. “Early South African geostatistical techniques in today’s perspective”. Geostatistics 1. 1989.
- Matheron1963
Matheron. “Principles of Geostatistics”. Economic Geology 58. 1963.
- Robinson1991
G.K.Robinson.“That BLUP is a good thing: the estimation of random effects”. Statistical Science 6.1. 1991. DOI: 10.1214/ss/1177011926.
- Bohling2005
Bohling. “Kriging”. Tech.rep. 2005.
- Forrester2006
Forrester, Alexander I.J, et al. “Optimization using surrogate models and partially converged computational fluid dynamics simulations”. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Science. 2006. DOI: 10.1098/rspa.2006.1679
- Forrester2009
Forrester and A.J. Keane.“Recent advances in surrogate-based optimization”. Progress in Aerospace Sciences 2009. DOI: 10.1016/j.paerosci.2008.11.001