3. Surrogate model¶
3.1. Generalities¶
A common class is used to manage surrogate models. Hence, several kind of surrogate model strategies can be used:
predictor = batman.surrogate.SurrogateModel('kriging', corners)
predictor.fit(space, target_space)
predictor.save('.')
points = [(12.5, 56.8), (2.2, 5.3)]
predictions = predictor(points)
3.2. From Kriging to Gaussian Process¶
3.2.1. Kriging, a geostatistical method¶
Kriging is a geostatistical interpolation method that use not only the distance between the neighbouring points but also the relationships among these points, the autocorrelation. The method has been created by D.G. Krige [Krige1989] and has been formalized by G. Matheron [Matheron1963].
In order to predict an unmeasured location  , interpolation methods use the surrounding measured values
, interpolation methods use the surrounding measured values  and weight them:
and weight them:

The advantage of this method is that the interpolation is exact at the sampled points and that it gives an estimation of the prediction error. Ordinary Kriging consists in the Best Linear Unbiased Predictor (BLUP) [Robinson1991]:
- Best
- It minimizes the variance of the predicted error
 ,
, - Linear
- A linear combination of the data,
- Unbiased
- It minimizes the mean square error
![E[\hat{Y} - Y]^2](../_images/math/da468ee94968f8af5ae9740096ade25169aee57f.svg) thus
thus  ,
, - Predictor
- It is an estimator of random effects.
 are calculated using the spatial autocorrelation of the data, it is a variography analysis. Plots can be constructed using semivariance, covariance or correlation. An empirical variogram plot allows to see the values that should be alike because they are close to each other cite{Bohling2005}. The empirical semivariogram is given by:
are calculated using the spatial autocorrelation of the data, it is a variography analysis. Plots can be constructed using semivariance, covariance or correlation. An empirical variogram plot allows to see the values that should be alike because they are close to each other cite{Bohling2005}. The empirical semivariogram is given by:

A fitting model is then applied to this semivariogram. Hence, the variability of the model is inferior to data’s. Kriging smooths the gradients. The exponential model is written as:

with  the correlation matrice and the parameter
the correlation matrice and the parameter  is optimized using the sample points.
is optimized using the sample points.
A model is described using:
- Sill
- It corresponds to the maximum of
 . It defines the end of the range.
. It defines the end of the range. - Range
- It is the zone of correlation. If the distance is superior to the range, there is no correlation, whereas if the distance is inferior to it, the sample locations are autocorrelated.
- Nugget
- If the distance between the points is null, should be null. However, measurement errors are inherent and cause a nugget effect. It is the y-intercept of the model.
Once the model is computed, the weights are determined to use the MSE condition and gives:

 being the covariance matrix
being the covariance matrix  and
and  being the covariance vector
being the covariance vector  with the covariance
with the covariance  .
.

Furthermore we can express the field  as
as  which is the residual and the trend components [Bohling2005]. Depending on the treatment of the trend, there are several Kriging techniques (ordinary Kriging being the most used):
which is the residual and the trend components [Bohling2005]. Depending on the treatment of the trend, there are several Kriging techniques (ordinary Kriging being the most used):
- Simple
- The variable is stationary, the mean is known,
- Ordinary
- The variable is stationary, the mean is unknown,
- Universal
- The variable is non-stationary, there is a tendency.
Ordinary Kriging is the most used method. In this case, the covariance matrix is augmented:

Once the weights are computed, its dot product with the residual  at the known points gives the residual
at the known points gives the residual  . Thus we have an estimation of . Finally, the error is estimated by the second order moment:
. Thus we have an estimation of . Finally, the error is estimated by the second order moment:

Some care has to be taken with this estimation of the variance. Being a good indicator of the correctness of the estimation, this is only an estimation of the error based upon all surrounding points.
3.2.2. Gaussian Process¶
There are two approaches when dealing with regression problems. In simple cases, we can use simple functions in order to approximate the output set of data. On the other hand, when dealing with complex multidimensional problems with strong non-linearity, there are infinite possibilities of functions to consider. This is where the Gaussian process comes in.
As stated by Rasmussen et al. in [Rasmussen2006], a process is a generalization of a probability distribution of functions. When dealing with Gaussian processes, they can simply be fully defined using the mean and covariance of the functions:
![f(x)&\sim GP(m(x), k(x,x')),\\
m(x) &= \mathbb{E}\left[ f(x) \right], \\
k(x,x') &= \mathbb{E}\left[ (f(x) -m(x))(f(x')-m(x')) \right].](../_images/math/19f2c43cc01ad838de4854c78ee9c4575ac4827d.svg)
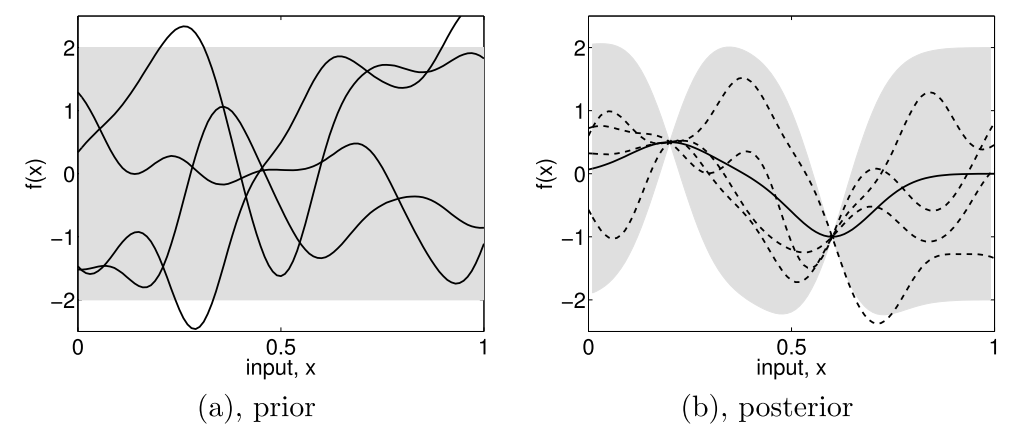
Subfigure (a) shows four samples from a prior distribution. (b) shows the situation after two observations have been made. [Rasmussen2006].
Starting from a prior distribution of functions, it represents the belief we have on the problem. Without any assumption, the mean would be null. If we are now given a dataset  , we only consider the function that actually pass through or close to these points, as in the previous figure. This is the learning phase. The more points are added, the more the model will fit the function. Indeed, as we add observations, the error is reduced at these points.
, we only consider the function that actually pass through or close to these points, as in the previous figure. This is the learning phase. The more points are added, the more the model will fit the function. Indeed, as we add observations, the error is reduced at these points.
The nature of the covariance matrix is of great importance as it fixes the properties of the functions to consider for inference. This matrix is also called kernel. Many covariance functions exist and they can be combined to fit specific needs. A common choice is the squared exponential covariance kernel:

with  the length scale, an hyperparameter, which depends on the magnitudes of the parameters. When dealing with a multidimensional case and non-homogeneous parameters, it is of prime importance to adimentionize everything as one input could bias the optimization of the hyperparameters.
the length scale, an hyperparameter, which depends on the magnitudes of the parameters. When dealing with a multidimensional case and non-homogeneous parameters, it is of prime importance to adimentionize everything as one input could bias the optimization of the hyperparameters.
Then the Gaussian process regression is written as a linear regression

One of the main benefit of this method, is that it provides an information about the variance
![\mathbb{V}[f(\mathbf{x}_*)] = k(\mathbf{x}_*, \mathbf{x}_*)-\mathbf{k}(\mathbf{x}_*)^T(K + \sigma_n^2 I)^{-1}\mathbf{k}(\mathbf{x}_*).](../_images/math/5ce2933dbb38dc1e8216b4f5d06bdf4e7a26e8fe.svg)
The Kriging method is one of the most employed as of today. We can even enhance the result of the regression if we have access to the derivative (or even the hessian) of the function [Forrester2009]. This could be even more challenging if we don’t have an adjoint solver to compute it. Another method is to use a multi-fidelity metamodel in order to obtain an even better solution. This can be performed if we have two codes that compute the same thing or if we have two grids to run from.
3.3. Polynomial chaos expansion¶
Some citations: [Blatman2009phd] [Lemaitreknio2010] [Migliorati2013] [Sudret2008] [Xiu2010] [Xiu2002]
Polynomial chaos expansion (PCE) is a type of surrogate model widely used in uncertainty quantification studies. It takes place in a stochastic framework where model inputs are random variables whose probabilistic distributions determine the families of polynomial regressors. We set out below the details of a PCE construction and its implementation with BATMAN.
3.3.1. Generalities¶
3.3.1.1. Input scaling¶
Let  be the random input vector defined in the input physical space
be the random input vector defined in the input physical space  . The
. The  component
component  of
of  is transformed into a new random variable
is transformed into a new random variable  obtained by the following centering and scaling operation:
obtained by the following centering and scaling operation:

where  and
and  are respectively the empirical mean and standard deviation of computed from a
are respectively the empirical mean and standard deviation of computed from a  -sample
-sample  . The random vector
. The random vector  evolves in a space noted
evolves in a space noted  .
.
3.3.1.2. Polynomial expansion¶
Let  be the random model output with values in
be the random model output with values in  . Assuming that the model output
. Assuming that the model output  is of finite variance, each component can be considered as a random variable for which there exists a polynomial expansion of the form:
is of finite variance, each component can be considered as a random variable for which there exists a polynomial expansion of the form:

where  is a basis of orthonormal polynomial functions:
is a basis of orthonormal polynomial functions:

with  and
and  the Kronecker delta function,
the Kronecker delta function,
and where  is the coefficient of the projection of
is the coefficient of the projection of  onto
onto  :
:

3.3.1.3. Polynomial basis¶
In practice, this orthonormal basis is built using the tensor product of  1-D polynomial functions coming from different orthonormal basis:
1-D polynomial functions coming from different orthonormal basis:

where  is the multi-index associated to the integer
is the multi-index associated to the integer  . The bijective application
. The bijective application  is an enumerate function to chose (see Enumerate strategies).
is an enumerate function to chose (see Enumerate strategies).
The choice for the basis functions depends on the probability measure of the random input variables  . According to the Askey’s scheme, the Hermite polynomials form the optimal basis for random variables following the standard Gaussian distribution:
. According to the Askey’s scheme, the Hermite polynomials form the optimal basis for random variables following the standard Gaussian distribution:

and the Legendre polynomials are the counterpart for the standard uniform distribution:

Note that even if standard uniform and Gaussian distributions are widely used to represent input variable uncertainty, the Askey’s scheme can also be applied to a wider set of distributions [Xiu2002].
3.3.1.4. Surrogate model¶
From a deterministic point of view, for a given realization  of and based on the previous variable change, we have:
of and based on the previous variable change, we have:

In practice, we use a truncation strategy (see Truncation strategies) limiting this polynomial expansion to the more significant elements in terms of explained output variance:

Thus,  is a surrogate model of
is a surrogate model of  .
.
3.3.2. Properties¶
Various statistical moments associated to the PC surrogate model have explicit formulations, thus avoiding Monte-Carlo sampling, even if this metamodel is computationally cheap.
For the  output, the expectation reads:
output, the expectation reads:
![\mathbb{E}\left[\hat{y}_j\left(\mathbf{X}\right)\right]=\gamma_{j,0}](../_images/math/21882d0db95ecb0d5777d543ff621ae23d1c04b5.svg)
For the output, the variance reads:
![\mathbb{V}\left[\hat{y}_j\left(\mathbf{X}\right)\right]=\sum_{i = 1}^r\gamma_{j,i}^2](../_images/math/47ccc4697e938e32fa5efd8cf525560285fa07a4.svg)
For the and  outputs, the expectation reads:
outputs, the expectation reads:
![\mathbb{C}\left[\hat{y}_j,\hat{y}_k\left(\mathbf{X}\right)\right]=\sum_{i = 1}^r\gamma_{j,i}\gamma_{k,i}](../_images/math/a83f7c3b254737c05bf8193e26ff4c87a3450349.svg)
In the context of global sensitivity analysis, there are similar results for the Sobol’ indices [Sudret2008].
3.3.3. Options¶
3.3.3.1. Enumerate strategies¶
Remind that:
 .
. are the
are the  first elements of the polynomial basis associated to
first elements of the polynomial basis associated to  and their degrees are lower or equal to
and their degrees are lower or equal to  .
. .
. .
.
An enumerate function is a bijective application from  to
to  of the form:
of the form:

The bijectivity property implies that the initial term is:

and the next ones satisfy the constraint:

or

Linear enumerate function
A natural linear enumerate strategy is the lexicographical order with a constraint of increasing total degree. The unique requirement of this strategy is the input space dimension .
Hyperbolic anisotropic enumerate function
Hyperbolic truncation strategy gives an advantage to the main effects and low-order interactions. From a multi-index point of view, this selection implies to discard multi-indices including an important number of non-zeros components.
![\forall q \in ]0, 1]](../_images/math/ae028dccd3be15e9b174164a30547e5204029874.svg) , the anisotropic hyperbolic norm of a multi-index
, the anisotropic hyperbolic norm of a multi-index  is defined by:
is defined by:

where the  ‘s are real positive numbers. In the case where
‘s are real positive numbers. In the case where  , the strategy is isotropic.
, the strategy is isotropic.
3.3.3.2. Truncation strategies¶
In this section, we present different truncation strategies.
Note that for small , advanced truncation strategies that consist in eliminating high-order interaction terms or using sparse structure [Blatman2009phd] [Migliorati2013] are not necessary.
Fixed truncation strategy
The standard truncation strategy consists in constraining the number of terms by the number of random variables and by the total polynomial degree of the PCE. Precisely, the choice of is equal to:

All the polynomials involving the random variables with a total degree less or equal to are retained in the PC expansion. Then, the PC approximation of is formulated as:

Warning
The number of terms grows polynomially both in and though, which may lead to difficulties in terms of computational efficiency and memory requirements when dealing with high-dimensional problems.
Sequential truncation strategy
The sequential strategy consists in constructing the basis of the truncated PC iteratively. Precisely, one begins with the first term  , that is
, that is  , and one complements the current basis as follows:
, and one complements the current basis as follows:  . The construction process is stopped when a given accuracy criterion is reached, or when
. The construction process is stopped when a given accuracy criterion is reached, or when  is equal to a prescribed maximum basis size .
is equal to a prescribed maximum basis size .
Cleaning truncation strategy
The cleaning strategy aims at building a PC expansion containing at most significant coefficients, i.e. at most significant basis functions. It proceeds as follows:
- Generate an initial PC basis made of the first polynomials (according to the adopted EnumerateFunction), or equivalently an initial set of indices
 .
. - Discard from the basis all those polynomials associated with insignificance coefficients, i.e. the coefficients that satisfy:

where  is the significance factor, default is
is the significance factor, default is  .
.
- Add the next basis term
 to the current basis
to the current basis  .
. - Reiterate the procedure until either terms have been retained or if the given maximum index
 has been reached.
has been reached.
3.3.3.3. Coefficient calculation strategies¶
We focus here on non-intrusive approaches to numerically compute the coefficients  using snapshots from
using snapshots from  .
.
Least-square strategy
Based on a -sample  , the least-square strategy seeks the solution of the optimization problem:
, the least-square strategy seeks the solution of the optimization problem:

which is achieved through classical linear algebra tools.
Note that the sample size required by this strategy is at least equal to  where is the number of PC coefficients and
where is the number of PC coefficients and  is the output vector dimension.
is the output vector dimension.
Quadrature strategy
The spectral projection relies on the orthonormality property of the polynomial basis. For the , the coefficient is computed using a Gaussian quadrature rule as:

where:
 is the evaluation of the simulator at the quadrature root
is the evaluation of the simulator at the quadrature root  of ,
of , is the weight associated to
is the weight associated to  .
.
Note that the number of quadrature roots required in each uncertain direction to ensure an accurate calculation of the integral  is equal to
is equal to  .
.
3.3.4. Implementation¶
Concerning the library BATMAN, polynomial chaos expansion has to be specified in the block surrogate of the JSON settings file, setting the keyword method at pc and eventually using ones of the following keywords:
| Keywords | Type | Description |
|---|---|---|
| strategy | string | Strategy for the weight computation:
|
| degree | integer | Total polynomial degree |
| distributions | list(openturns.Distribution) |
Distributions of each input parameter |
| n_sample | integer | Number of samples for least square |
3.4. Multifidelity¶
It is possible to combine several level of fidelity in order to lower the computational cost of the surrogate building process. The fidelity can be either expressed as a mesh difference, a convergence difference, or even a different set of solvers. [Forrester2006] proposed a way of combining these fidelities by building a low fidelity model and correct it using a model of the error:

with  the surrogate model representing the error between the two fidelity levels.
This method needs nested design of experiments for the error model to be computed.
the surrogate model representing the error between the two fidelity levels.
This method needs nested design of experiments for the error model to be computed.
Considering two levels of fidelity  and
and  , respectively an expensive and a cheap function expressed as a computational cost. A cost ratio
, respectively an expensive and a cheap function expressed as a computational cost. A cost ratio  between the two can be defined as:
between the two can be defined as:

Using this cost relationship an setting a computational budget , it is possible to get a relation between the number of cheap and expensive realizations:

As the design being nested, the number of cheap experiments must be strictly superior to the number or expensive ones. Indeed, the opposite would result in no additional information to the system.